Sprogteknologi // Language Technology
![]()
Sprogteknologi // Language Technology
Ressourcen er udarbejdet af Jørg Asmussen, DSL.
JournaDa er en diakron samling af korpusser med sætninger i tilfældig orden, som stammer fra danske nyhedstekster. Korpusset omfatter ca. 15-45 millioner ord per år fra 2005 og fremefter, i alt over 500 millioner ord. For hvert år er materialet samlet i én zip-fil.
OBS! Af ophavsretlige grunde består disse korpusser af sætninger eller mindre udsnit (citater) blandet i tilfældig orden. Korpusserne indeholder ikke tekster i deres helhed.
Materialet er lemmatiseret og ordklassetagget med ePOS-tagsættet.
Hver zip-fil indeholder en mappe med 10.000 tekstfiler. Filernes format er kompatibelt med det, der bruges i IMS Open Corpus Workbench (CWB/CQP).
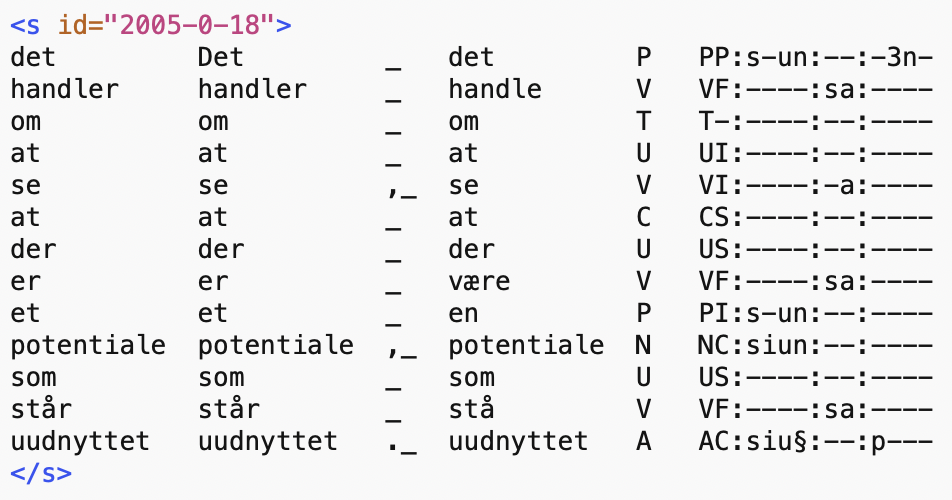
Hver fil indeholder et stort antal sætninger, hver sætning er omgivet af <s>-tags. Hvert ord i en sætning står på sin egen linje, som består af seks enheder afgrænset fra hinanden ved tabulatortegn:
Eksempel på en sætning:
Før du downloader materialet, skal du acceptere betingelserne vedrørende ophavsret, brug og kreditering.
Compiled by Jørg Asmussen, DSL.
JournaDa is a diachronic collection of corpora comprising random sentences from Danish news media with approximately 15-45 million words per year from 2005 and onwards, currently totalling more than 500.000 million words. The material for each year is contained in a zip-file.
OBS! Due to copyright reasons, these corpus resources comprise sentences or shorter excerpts in arbitrary order. They do not contain full texts.
The corpus is lemmatized and POS-tagged with the ePOS tag set.
Each zip-file contains a folder with 10.000 text files. The format of these files is compatible with the IMS Open Corpus Workbench (CWB/CQP).
Each file comprises a large number of sentences, each sentence surrounded by <s> tags. A sentence is subdivided into words, one word per line. Each line consists of six tab-divided units:
The following is an example sentence taken from the material:
Before downloading this material, you must accept the conditions for copyright, use, and crediting that apply.